Paper: Classical Probabilistic Models and Conditional Random Fields
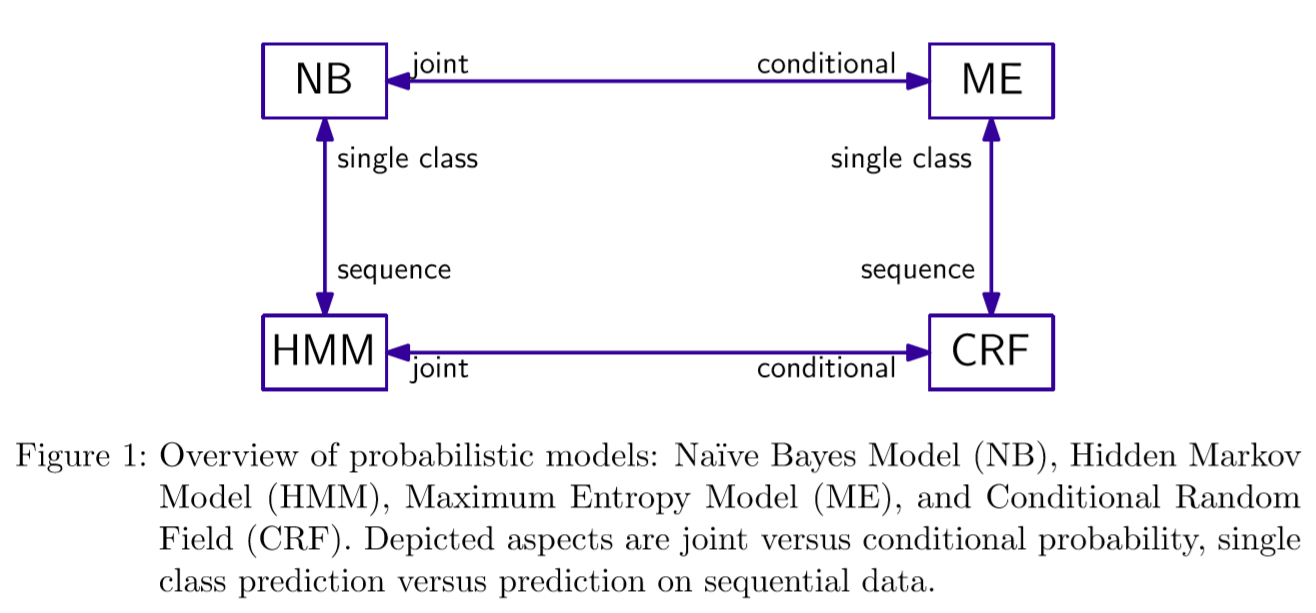
先放出这篇论文的核心图:
熵
自信息量
一个事件本身所包含的消息量,由事件不确定性决定
随机事件 $x_i$ 发生概率为 $p(x_i)$ , 自信息量定义为
log以2为底,单位bit
信息熵
自信息量的期望,最短编码长度
条件熵
给定X的条件下,Y 的信息熵还有多少
联合熵
X,Y同时发生的不确定性度量
互信息
信息增益, 给定Y,X不确定性减少的度量
交叉熵
用估计得q概率分布去编码,真实概率是p,得到的平均编码长度
相对熵
KL散度,一定程度上看成两个随机变量距离的度量,编码长度不完美时平均编码长度得增大值
我们希望最小化相对熵,因为真实概率 是固定得,等价于最小化交叉熵,等价于MLE(这个要回去看一下deep learning5.5)
最大熵原理
Principle of maximum entropy: :the probability distribution which best represents the current state of knowledge is the one with largest entropy, in the context of precisely stated prior data
By Wiki
条件最大熵模型
(这里论文里叫最大熵模型,但我查了一下最大熵似乎是model p(x)的原理都一样,这个是条件最大熵模型)
也叫softmax回归模型(另一角度),是一种条件概率模型(判别式模型),根据最大熵原理我们选择
P是所有和训练集“一致”的概率分布,如何定义”一致”如下:
给定训练集 $\Gamma = \{(x_1,y_1),\ldots,(x_N,y_N)\}$ 和 m个特征函数 $f_i(x,y) \in \{0, 1\}$
那么特征函数估计得期望是
其中 $\tilde{p}(x,y)$ 简单得用训练集中出现得次数来估计
真实的 特征函数期望值是
往往x的可能取值很多,而集合Y比较小, 为了有效得计算期望,我们重写成上面的形式之后,用训练集中x的分布逼近真实的x分布得到
“一致” 的概率分布需要满足:
拉格朗日乘子法得
和前面同样的,条件熵如下近似
推出
应用(1)式子得到
是一个log-linear的模型,概率图模型就是Naive Bayes图模型(有向)的无向图版本…其中exp可以看作因子图中的势能函数,能量函数是特征函数的线性加权
条件随机场
也是一种直接建模条件概率的无向图模型,可以看作条件最大熵的sequence版本,并且不限制于HMM的线性结构
观察变量 $\vec{x} = \{x_1,\ldots,x_n\}$ ,预测变量/隐变量 $\vec{y} = \{y_1, \ldots, y_n\}$
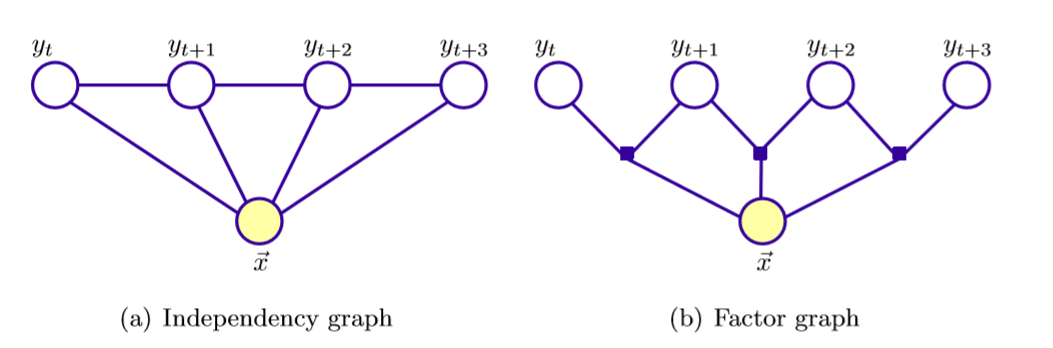
根据无向图的因子图中联合概率的形式
我们推导出条件概率的形式为
(??这就叫条件随机场了)
Linear-chain CRFs
隐变量是链式结构 ,假设链长 n + 1
那么
定义势函数的形式是
所以
因为最大团模板只有一个 $C = \{\Phi_j(y_j,y_{j-1},\vec{x})\mid \forall j \in \{1,\ldots,n\}\}$ 所以可以用一个全连接的SFSA(stochastic finite state automaton) 来表示(这里不是特别明白)
对于高阶的linear-CRF 特征需要涉及前k个隐变量序列
##### maximum-likelihood
防止过拟合,加入惩罚项
可以从偏导项看出是一个凹函数(????中间的那一项怎么理解)
这里省去了前面的常数 $\frac{1}{N}$ , 不影响结果
但是因为 $\vec{y} \in Y$ 可能的所有取值太多了,所以用forward-backward来方便的计算 $E[f_i]$
##### inference
算法就是Viterbi算法