PRML: Chapter8
Probabilistic graphical model
概率图模型提供了一种概率模型直观的可视化方法,从中我们可以获取比如条件独立等信息,并且可以方便的表示出联合概率分布。可以划分为有向概率图(贝叶斯网络)和无向概率图(马尔可夫随机场)。
Bayesian Networks
也叫信念网络(belief network)/有向无环图模型,顶点对应随机变量,从y到x的有向边代表条件概率 $p(x\mid y)$ .如果顶点x共有从 $y_1,\ldots,y_k$ 的顶点到其有边,那么条件概率是 $p(x\mid y_1,\ldots,y_k)$ 。它可以表示图中变量的联合分布为条件概率的乘积
d-separation
D-分离是一种判断变量是否条件独立的图形化方法。
考虑三个变量 a, b, c的概率图模型,c有以下三种:
- tail-to-tail
a <- c -> b- c未被观察到,ab不独立
- c被观察到(Condition on c), $a \perp b \mid c$
- head-to-tail
a -> c -> b- c未被观察到,ab不独立
- c被观察到, $a \perp b \mid c$
- head-to-head
a -> c <- b- c未被观察到, $a \perp b \mid \phi$
- c(或c的后代)被观察到,ab不条件独立
广义地,给出有向图中互不相交点集A,B,C的阻塞(block)和D-分离的定义
连接A集合任意一点和B集合任意一点的任意一条路径被阻塞,如果满足下面条件之一
(1)在点c满足head-to-tail或tail-to-tail结构,c在C中
(2)在点c满足head-to-head结构,c和c的后代都不在C中
如果所有的路径都被阻塞,那么C有向分离A和B: $A \perp B \mid C$
补充:对于head-to-head结构,比如交通堵塞 $e_1$ 、钟表坏了 $e_2$、上学迟到 $e_3$ ,$e_1$ 和 $e_2$ 都是 $e_3$ 的可能原因,$e_1$ 和 $e_2$ 本来是独立事件,但如果我们观察到 $e_3$ 发生了,那么如果 $e_1$ 没发生,很可能 $e_2$ 会发生…
I-maps
Defn:
- 概率分布P(X), I(P)表示P分布中成立的条件独立断言
- 图K, 如果K中的条独立性质集合I(K)是I的子集,称K是独立性质集合I的I-map
- 图G是概率P的I-map 如果G是I(P)的I-map(也就是G中的独立P中都成立,P可能包含更多)
The Equivalence Theorem
对于图G,D1代表所有满足I(G)的分布集合,D代表所有可以分解成G的分布集合,那么D1等于D2??
d-separation theorem
Markov Blanket
在随机变量全集U中,对于给定变量 $X \in U$ 和变量集 $S \subset U(X \notin S)$, 如果有
则称满足上述条件的最小变量集S为X的马尔科夫毯
特别地,在贝叶斯网络中,变量X的马尔科夫毯 = {X的父亲,X的孩子, x配偶},而在无向图模型中,变量X的马尔科夫毯 = {所有和X有边连接的顶点变量}
Markov random field
也叫马尔科夫网络(Markov Network)或无向图模型,无向图判断条件独立
如果A任意一个结点和B任意一点之间的任意一条路径都至少有一个点属于C, A,B,C互不相交,那么 $A \perp B \mid C$
联合分布可以写成定义在最大团变量上的势函数 $\psi$ (potential function 要求 大于 0)的乘积
其中Z有时被称作划分函数(partition function),是一个归一化常数
C是最大团, $\mathbf{x}_C$是最大团中的变量
因为势函数是严格正的,我们可以定义其为
E被称作能量函数
和有向图联合概率分布不同,无向图中的势函数并没有一个具体的概率解释
Hammersley-Clifford theorem
I map/D map/perfect map
Inference in Graphical Models
(下面都基于x离散值,连续值可以同理用积分扩展)
chain
对于图模型的推理,我们首先考虑无向图的链式结构:马尔科夫链(有向图的链可以不加边转换为无向图表示相同条件独立性),那么变量的联合分布为
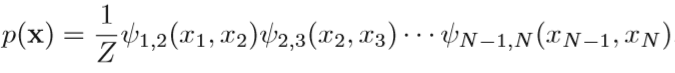
$x_n$ 的边缘分布可以写成
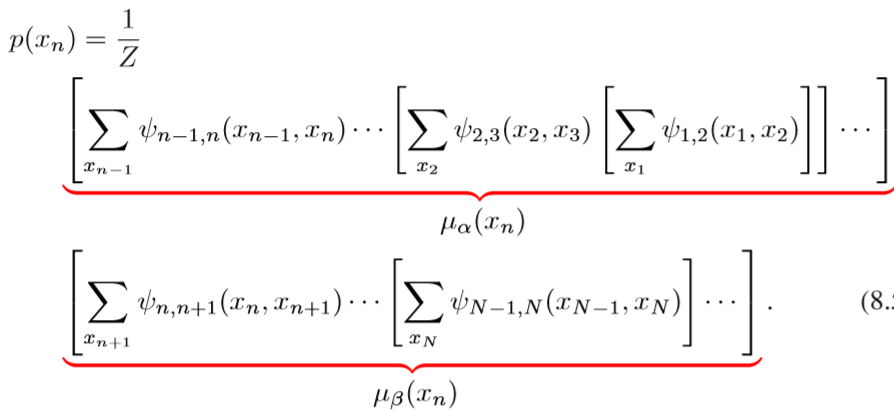
其中 $\mu_{\alpha}(x_n)$ 看作 $x_{n-1}$ 到 $x_n$ 沿链传递的信息, 同样的, $\mu_{\beta}(x_{n})$ 可以看作从 $x_{n+1}$ 到 $x_n$ 回传的信息
那么两者可以递归的写成

因此如果要计算所有变量的边缘分布,我们只需从左到右和反向计算两边即可
如果要获取两个邻接变量的联合概率分布
连续两个变量的联合概率分布是
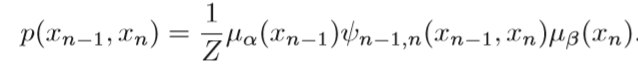
tree
- undirected tree
- directed tree(可以转换为无向图的树不加任何边)
- polytree(有向图,忽略边方向是树,但是存在结点有多个父亲,加边转为无向图可能破坏树结构)
上面三种转换为因子图都可以转换为树结构
factor graphs
包含表示变量的结点和因子的结点,一个有向图/无向图可能对应多个因子图,首先定义变量集合的联合分布为
因子 $f_s$ 是一个定义在变量集合 $\mathbf{x}_s$ 上的函数,有向图中它可以对应为条件概率分布,无向图中可以对应为最大团变量上的势函数,因子图是一个二分图(因子结点和变量结点之间才有边)
sum-product algorithm
有效地求边缘分布的算法。
我们考虑上面所说三种情况,令因子图中变量x是树根,那么
其中ne(x)是所有x连接的因子, $X_s$代表通过s和x相连的变量, $F_s$ 代表通过s和x相连的因子以及s的乘积,那么边缘分布
定义 $\mu_{f_s \rightarrow x}(x) = \sum_{X_s}F_s(x,X_s)$ 看作从因子 $f_s$ 传给变量x的信息
同样展开调整求和顺序, $f_s$ 直接相邻的集合 $\mathrm{x}_s = \{x,x_1,\ldots,x_M\}$
$G_m$ 代表和 $x_m$ 相连的因子(除了s)的乘积, $X_{sm}$ 是通过 $x_m$ 和因子s相连的变量集,定义 $\mu_{x_m \rightarrow f_s}(x_m) = \sum_{X_{sm}}G_m(x_m,X_{sm})$ 看作从变量到因子传递的信息
递归的,我们有
因此
根据前面的推导,如果叶结点是变量
如果叶节点是因子,那么
因此我们选定一个结点为根,从叶子结点到根传递信息一遍,再从根到叶子返回传递一遍信息,就能得到所有变量的边缘分布
同样的方法,推导出和因子s连接变量集合的联合概率分布是
关于分布的正则化,从有向图得到的因子图推理得到的概率分布已经是归一化的,而无向图需要乘以 $\frac{1}{Z}$ 其中Z等于在一个变量x的所有可能取值概率(没有归一化)加和,我们不需要在所有变量集的可能取值上归一化
上面的推理都基于我们没有观测到任何x值,要扩展到给定观察变量集v,其观察值为 $\hat{v}$ 隐变量集h的条件概率分布为
I是指示函数,也就是我们可以算出 $p(\mathbf{h,v = \hat{v}})$ ,把分母当作归一化常数来计算( $p(h_i \mid \mathbf{v = \hat{v}})$ 所有可能取值加和)
max-sum algorithm
求 $\mathbf{x}^{max} = \underset{\mathbf{x}}{\mathrm{argmax}}p(\mathbf{x})$ 的算法
还是以简单的链式为例,由于势函数是严格正的,因此我们可以调整max操作如下
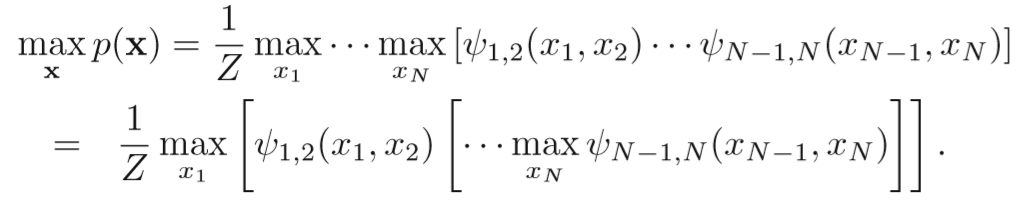
可以看作是从N结点到1结点的信息传递,那么树形同理,从叶子到根推理一遍即可。
但是小概率的乘积往往会有下溢等精度问题,实际常用log形式,而log是增函数,有下列性质
因此取对数之后只是把上面的乘积换成对数和的形式,因此我们获得了max-sum算法
其中叶子节点
这样从叶子节点到根信息传递一遍之后我们得到了最大的概率,然而一个最大概率对应变量的取值可能有多个,因此我们不能只反向传递信息的同时应用(1)式来获得取最大值的变量
other problem
在非上述情况的图模型上,想要做确切的推理有junction tree algorithm(核心还是max-sum)等等,然而受原始概率图的tree-width等性质影响它的计算效率,实际上,我们倾向于近似推理的方法,比如variational methods/sampling methods,其中一个很简单有环形图上的近似推理方法是loopy belief propagation,它的核心是忽略了途中的环,用上面的方法进行信息传递,在有环的地方信息会多次传递,直到收敛(或者根本不收敛)停止…除此之外还有怎么估计图模型等问题